Group by en SQL Server
Al requerir agrupar registros de una consulta nos viene la mente la cláusula Group by que tiene disponible SQL Server; que hace la función de los ciclos o subqueries.
La sintaxis básica de esta cláusula es la siguiente:
SELECT columnas
FROM NombreTabla
GROUP BY NombreColumna1, NombreColumna2,...;Aunque parezca algo muy simple, ahora que lo veamos en funcionamiento te darás cuenta lo útil que es.
Funcionamiento de group by en SQL
Para los ejemplos de funcionamiento, utilizaremos la tabla de empleados de la base de datos Northwind.

En el primer ejemplo resolveremos el siguiente problema: Agrupar las ciudades por país.
SELECT [EmployeeID],[LastName],[FirstName],[City],[Country]
FROM [Northwind].[dbo].[Employees]
GROUP BY [Country];Al ejecutar este código aparecerá el siguiente error de salida.

Te preguntaras porque, si estas siguiente la sintaxis correctamente; este error se genera debido a que las columnas de salida deben estar agregadas en el group by (a menos que sean algunas funciones). Por lo tanto, para evitar el error debemos de modificar la consulta de la siguiente manera.
SELECT [City],[Country]
FROM [Northwind].[dbo].[Employees]
GROUP BY [City],[Country];Colocamos las dos columnas del resultado en la cláusula group by, lo que nos da el siguiente resultado.
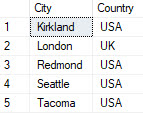
Lo que sucedió fue que en el resultado aparecen ciudades distintas en cada país, si una ciudad estaba mas de una ves en un mismo país en el resultado solo se tomara una.
Podría interesarte Procedimientos almacenados en SQL Server
Como mencionamos anteriormente, podemos agregar alguna función en el resultado de la consulta; esta es la parte más interesante de esta cláusula.
Para mostrar este ejemplo resolvamos lo siguiente: Obtener el número de empleados por país.
SELECT [Country], COUNT(*) AS 'Total'
FROM [Northwind].[dbo].[Employees]
GROUP BY [Country];Lo que haca la consulta es contar el número de veces que aparece el país mediante la función count(); lo que nos genera el resultado siguiente.

Esta es la forma más eficiente de obtener este tipo de valores, otra manera seria mediante una subconsulta; por rendimiento cuando existen miles de registros se recomienda group by.
Vimos algunos posibles usos; sin embargo, le puedes agregar más clausulas para consultas más complejas como Inners, where, order by, etc.